
Metadata for machine learning: models
What metadata do we need for machine learning? Part 1

I previously touched on why metadata is essential for machine learning. In this post, I will dig into this topic in more detail and focus on the what and how of metadata for machine learning. Through this, we should also arrive at a better understanding of the why.
What do we mean by metadata for machine learning?
As a brief reminder, metadata is ‘data about data’. We get a more helpful definition once we go into the purpose of metadata: “Metadata is defined as the data providing information about one or more aspects of the data; it is used to summarize basic information about data that can make tracking and working with specific data easier.”1

Metadata helps us understand and work with data better. There is no reason we can’t expand ‘data’ to other things. In this case, these ‘things’ are the artefacts of machine learning systems. So what are these things?
What are we creating metadata for?
When people think of ‘what’ machine learning is, they often think of a process or system. This process is often the training process used to create a model —more on this later — and the system is often a piece of software that uses machine learning, i.e. ChatGPT.
Plenty of metadata/data could be captured in a system like ChatGPT. Indeed, one of the significant worries about ChatGPT is the amount of data it tracks about a user: logs of what was said, when, what device was used, and how this data is leveraged for further model training. To keep the scope of this post somewhat constrained, I’ll focus only on metadata about ‘machine learning artefacts’.
Machine learning artefacts
“an object made by a human being, typically one of cultural or historical interest.”
An artefact is “an object made by a human being, typically one of cultural or historical interest.”2 What ‘objects’ are we talking about when discussing machine learning artefacts? Two things are required for most machine learning systems: a machine learning model and a dataset on which to train this model.

Metadata for a Machine Learning Model
When we talk about a ‘machine learning model’, it can sound like we are referring to a straightforward object at which we can point metadata.

In reality, what a machine learning model is is more tricky to pin down. A machine learning model can refer to:
The code used to define a model, i.e. the Python code
The architecture of the model, i.e. a ResNet 34 model
The learned weights of a model
A bunch of other things…
Let’s look at an example of a popular machine learning model to understand better what a ‘machine learning model’ can consist of. We'll see many files if we look at the files inside the model repository for the bert-base-uncased model on the Hugging Face Hub.
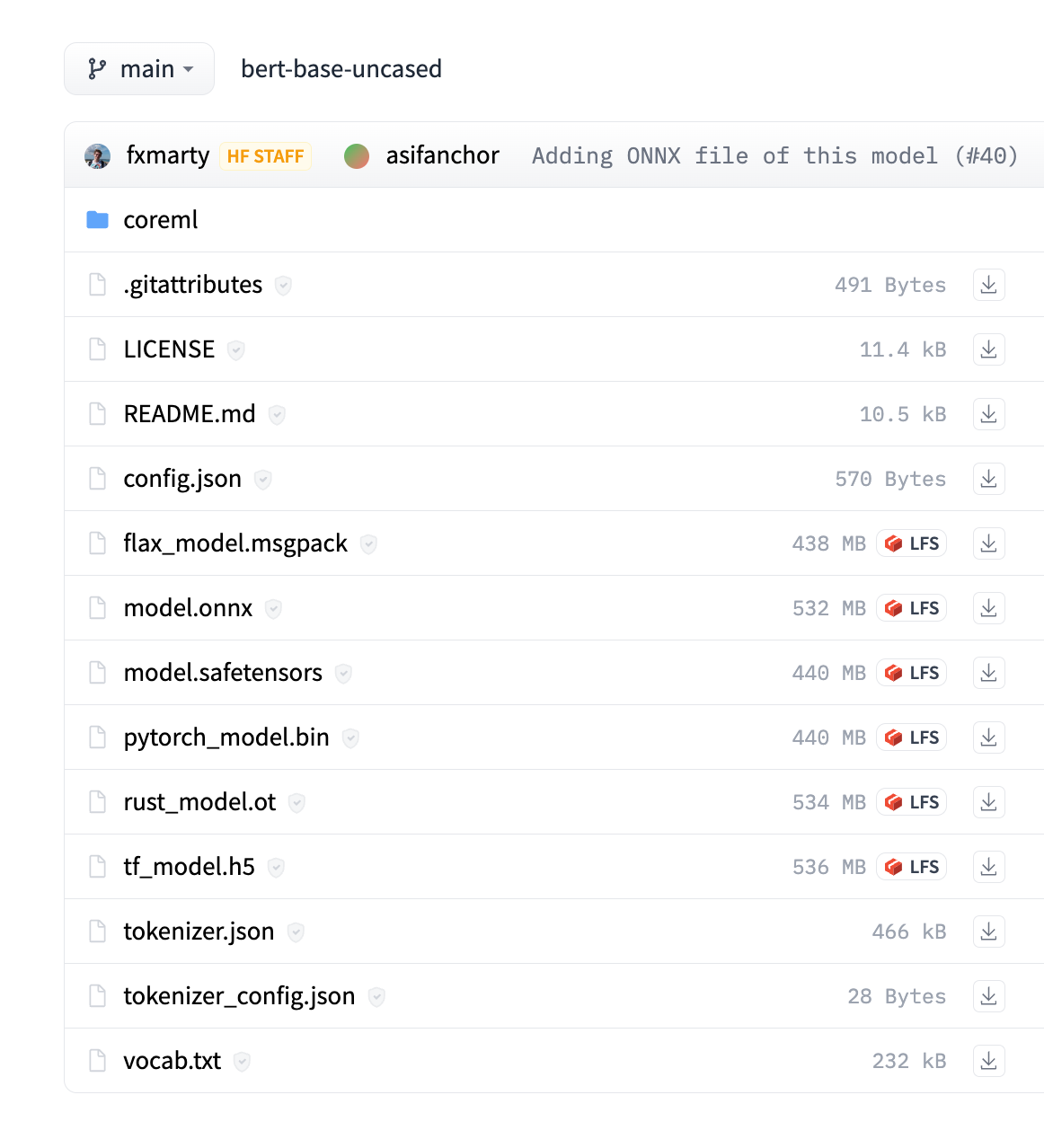
Some of these files support particular libraries using a model (the coreml folder, for example). Regardless, a few components are required for even the simplest version of a machine learning model:
A configuration file for the model
The model weights, i.e. what was ‘learned’ during training
The configuration for the tokenizer
The model vocabulary.
We can already see that we are not referring to a single object. All these different pieces of a model come together to make up a ‘machine learning model’. In the case of the Hugging Face Hub, the ‘machine learning model’ is usually a repository containing various files that make up a machine learning model.
We can quickly understand one goal metadata might help us achieve when looking at all the files associated with this machine learning model: enabling the use of the model. For most people, all of these files in themselves are not interesting. They want to be able to use the model.
Metadata for enabling model reuse
Being able to reuse someone else’s model is great. You save the effort (and carbon impact of training your own model), and for many people and use cases, training your own model is simply not possible.
One of the primary challenges with early machine learning software was reliably sharing a model with someone else and knowing that they could run a model you had trained for a particular task. Today, we can often call some code like this:
from transformers import pipeline
pipe = pipeline("fill-mask", model="bert-base-uncased")
And be able to use the model similarly to any other Python function.
Loading many machine learning models via a simple API was one of the breakthroughs created in the Transformers library (and supported by the Hub).
Previously, running machine learning models would often involve a fair bit of time banging your head against the wall trying to reproduce what the original model authors had done. This process didn’t always end successfully.
Most machine learning libraries now try to provide accessible methods for saving and loading models. How libraries know how to do this loading is often reliant on some metadata associated with ‘the model’ and, in the case of a model hosted on the Hugging Face Hub, part of what is stored in the repository for the model.
If we look at the config.json file in the bert-base-uncased repo;
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.6.0.dev0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 28996
}
this file essentially defines metadata about what the model looks like. Defining a consistent way for sharing this metadata is one of the parts of the bigger picture of what makes it possible to share machine learning models more easily.
one of the primary goals of metadata for machine learning models is to enable someone else to reuse the model.
There is a bunch of detail about precisely how a library processes this information, but in a large part, this doesn’t matter too much. The point here is that one of the primary goals of metadata for machine learning models is to enable someone else to reuse the model.
When things change…
Since the repository, which makes up a machine learning model on the Hugging Face Hub, is backed by the Git version control system, we also have some additional metadata, which we would associate with a machine learning system, i.e. the date when files were changed.
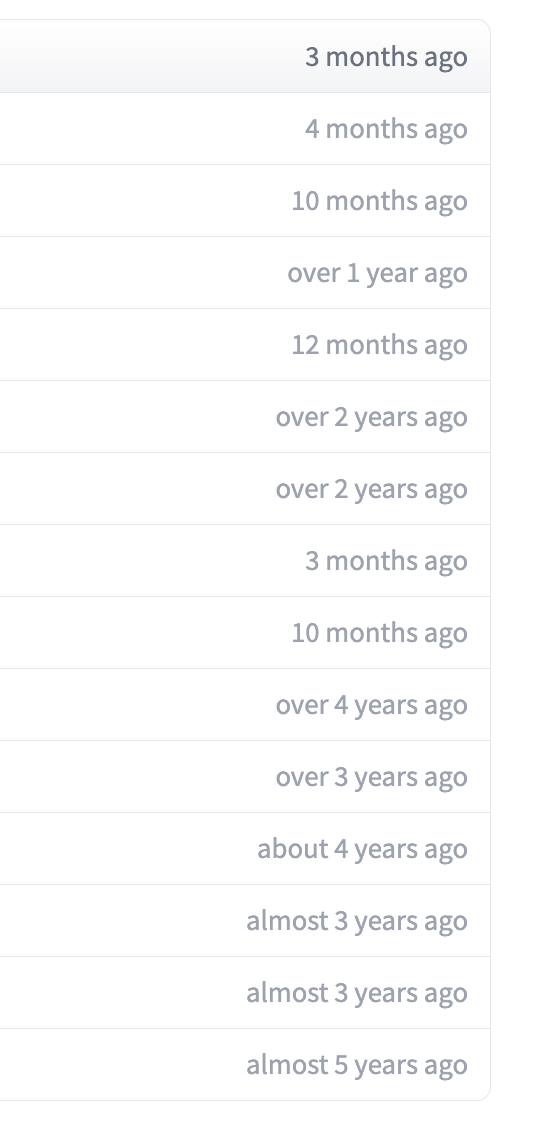
Whilst this file-level metadata might seem like it could be more interesting, it lets us know if and how a model has changed over time. Some of these changes might be pretty small, but in other scenarios, they could represent a more significant change in a model, i.e. a change in the labels used for the model. This basic metadata can be massively powerful for enabling the appropriate use of a model.
Next time…
In this post, we’ve focused on using a machine learning model. In the next post, we’ll return to finding machine learning artefacts using metadata and, specifically, how you can use metadata to help find the best model for your use case.
I’m delighted to hear from you if you have any questions or comments!
Oxford English Dictionary