
Exploring language metadata for datasets on the Hugging Face Hub

%pip install huggingface_hub backoff wordcloud tabulate toolz matplotlibRequirement already satisfied: huggingface_hub in ./.venv/lib/python3.11/site-packages (0.15.1)
Requirement already satisfied: backoff in ./.venv/lib/python3.11/site-packages (2.2.1)
Requirement already satisfied: wordcloud in ./.venv/lib/python3.11/site-packages (1.9.2)
Requirement already satisfied: tabulate in ./.venv/lib/python3.11/site-packages (0.9.0)
Requirement already satisfied: filelock in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (3.12.2)
Requirement already satisfied: fsspec in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (2023.6.0)
Requirement already satisfied: requests in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (2.31.0)
Requirement already satisfied: tqdm>=4.42.1 in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (4.65.0)
Requirement already satisfied: pyyaml>=5.1 in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (6.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (4.7.1)
Requirement already satisfied: packaging>=20.9 in ./.venv/lib/python3.11/site-packages (from huggingface_hub) (23.1)
Requirement already satisfied: numpy>=1.6.1 in ./.venv/lib/python3.11/site-packages (from wordcloud) (1.25.0)
Requirement already satisfied: pillow in ./.venv/lib/python3.11/site-packages (from wordcloud) (10.0.0)
Requirement already satisfied: matplotlib in ./.venv/lib/python3.11/site-packages (from wordcloud) (3.7.1)
Requirement already satisfied: contourpy>=1.0.1 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (1.1.0)
Requirement already satisfied: cycler>=0.10 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (4.40.0)
Requirement already satisfied: kiwisolver>=1.0.1 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (1.4.4)
Requirement already satisfied: pyparsing>=2.3.1 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (3.1.0)
Requirement already satisfied: python-dateutil>=2.7 in ./.venv/lib/python3.11/site-packages (from matplotlib->wordcloud) (2.8.2)
Requirement already satisfied: charset-normalizer<4,>=2 in ./.venv/lib/python3.11/site-packages (from requests->huggingface_hub) (3.1.0)
Requirement already satisfied: idna<4,>=2.5 in ./.venv/lib/python3.11/site-packages (from requests->huggingface_hub) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in ./.venv/lib/python3.11/site-packages (from requests->huggingface_hub) (2.0.3)
Requirement already satisfied: certifi>=2017.4.17 in ./.venv/lib/python3.11/site-packages (from requests->huggingface_hub) (2023.5.7)
Requirement already satisfied: six>=1.5 in ./.venv/lib/python3.11/site-packages (from python-dateutil>=2.7->matplotlib->wordcloud) (1.16.0)
Note: you may need to restart the kernel to use updated packages.from huggingface_hub import list_datasets
from toolz import valmap, countby, groupby, topk, valmap
from wordcloud import WordCloud
import matplotlib.pyplot as pltLoad datasets
datasets = list(iter(list_datasets(full=True, sort="downloads", direction=-1)))def get_lang(dataset):
card_data = dataset.cardData
if card_data:
lang = card_data.get("language")
if lang is None:
return False
if len(lang) >= 1:
return True
if not card_data:
return "No card data"has_lang = groupby(get_lang, datasets)has_lang.keys()dict_keys([True, 'No card data', False, None])has_language_freqs = countby(get_lang, datasets)
has_language_percents = valmap(
lambda x: round(x / sum(has_language_freqs.values()) * 100, ndigits=2),
has_language_freqs,
)
plt.style.use("ggplot")
data = {True: 13.31, "No card data": 42.03, False: 44.5}
# Convert the keys to strings
keys = [str(key) for key in data]
# Separate the values from the dictionary
values = list(data.values())
# Create a bar chart
plt.bar(keys, values)
# Set the labels for x and y axes
plt.ylabel("Percent")
# Set the title of the chart
plt.title("Has language information?")
# Display the chart
plt.show()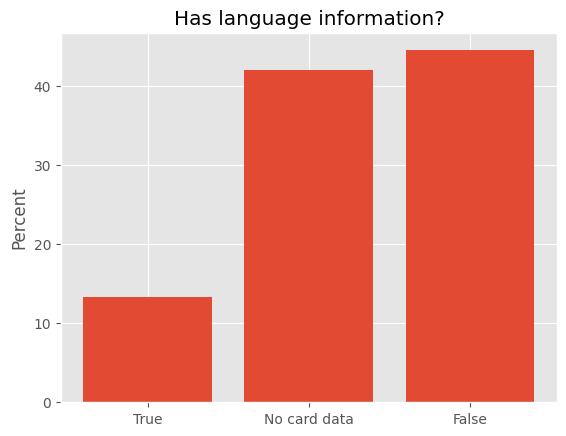
Filter to datasets with language information
with_lang = has_lang[True]def count_langs(dataset):
langs = dataset.cardData.get("language")
return len(langs)Top ten most frequent languages amounts
countby(count_langs, with_lang).items(), key=lambda x: x[1]topk(10, countby(count_langs, with_lang).items(), key=lambda x: x[1])((1, 5107),
(2, 662),
(3, 76),
(4, 35),
(6, 28),
(11, 26),
(7, 23),
(5, 20),
(12, 19),
(10, 18))highest number of languages
max(countby(count_langs, with_lang).keys())641Get languages
def get_langs(dataset):
return dataset.cardData.get("language")from toolz import concat, frequencieslang_freqs = frequencies(concat(get_langs(d) for d in with_lang))Number of unique languages specified on the hub
len(lang_freqs.keys())1719import pandas as pd---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[19], line 1
----> 1 import pandas as pd
ModuleNotFoundError: No module named 'pandas'df = pd.DataFrame({"Language": lang_freqs.keys(), "Frequency": lang_freqs.values()})
dfLanguage Frequency 0 en 3949 1 ja 221 2 ace 19 3 acm 6 4 acq 5 ... ... ... 1714 mr- 1 1715 xx 1 1716 nbl 2 1717 sep 1 1718 ssw 2
1719 rows × 2 columns
df.sort_values("Frequency", ascending=False).iloc[:20].set_index("Language").plot.bar()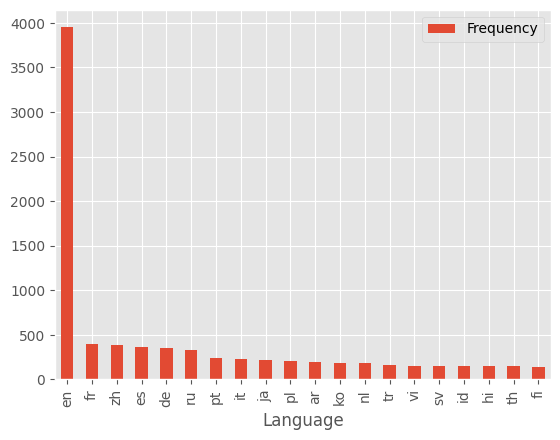
df["Percent"] = (df.Frequency / df.Frequency.sum() * 100).round(3)print(
df.sort_values("Frequency", ascending=False)
.iloc[:20]
.set_index("Language")
.to_markdown()
)| Language | Frequency | Percent |
|:-----------|------------:|----------:|
| en | 3949 | 19.04 |
| fr | 394 | 1.9 |
| zh | 390 | 1.88 |
| es | 358 | 1.726 |
| de | 350 | 1.687 |
| ru | 333 | 1.606 |
| pt | 238 | 1.147 |
| it | 229 | 1.104 |
| ja | 221 | 1.066 |
| pl | 207 | 0.998 |
| ar | 195 | 0.94 |
| ko | 184 | 0.887 |
| nl | 182 | 0.877 |
| tr | 156 | 0.752 |
| vi | 155 | 0.747 |
| sv | 153 | 0.738 |
| id | 149 | 0.718 |
| hi | 148 | 0.714 |
| th | 145 | 0.699 |
| fi | 144 | 0.694 |df = df.drop(columns="Percent")df.sort_values("Frequency", ascending=False).iloc[:20].set_index("Language").plot.barh()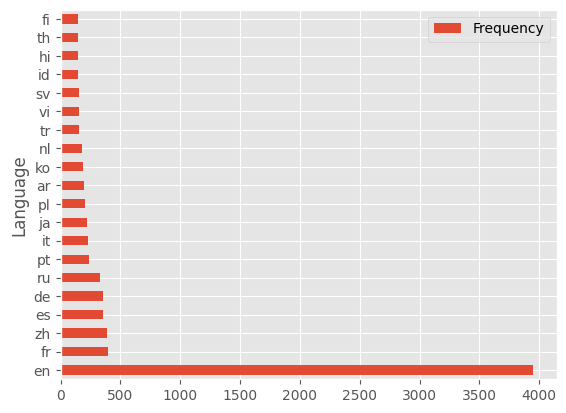
fig, ax = plt.subplots(figsize=(10, 6))
df[df.Language != "en"].sort_values("Frequency", ascending=False).iloc[:50].set_index(
"Language"
).plot.bar(ax=ax)
ax.set_xlabel("Language")
ax.set_ylabel("Frequency")
ax.set_title("Top 50 Languages (excluding English)")
plt.show()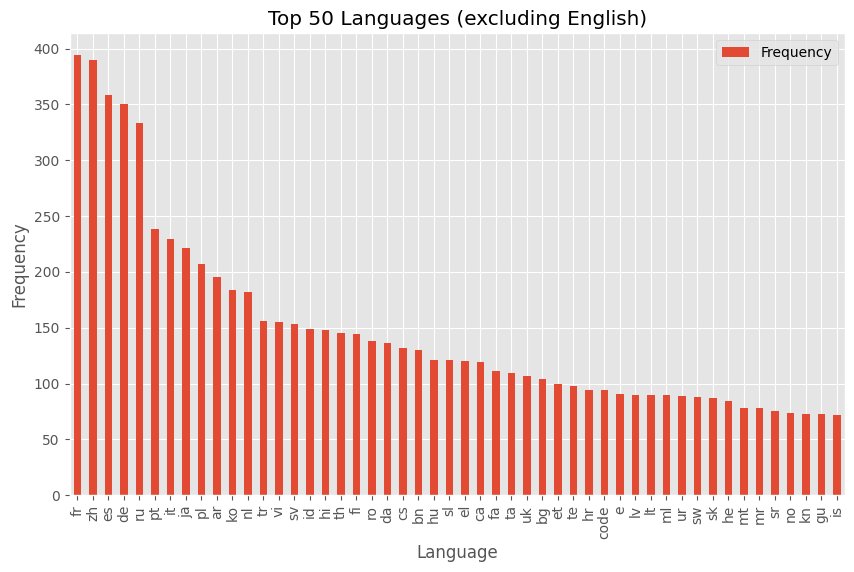
from matplotlib.colors import LinearSegmentedColormap
# Define Hugging Face brand colors
hugging_face_colors = ["#FFD21E", "#FF9D00", "#6B7280"]
# Create custom colormap
color_map = LinearSegmentedColormap.from_list("hugging_face", hugging_face_colors)wordcloud = WordCloud(width=800, height=400, colormap=color_map)
wordcloud.generate_from_frequencies(lang_freqs)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()